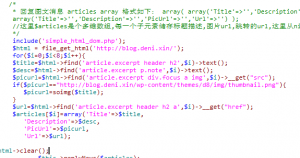
php用file_get_content获取内容后还要用preg_match写正则,不好处理数据,用这个simple_html_dom之后解析html文档就相当方便了.
先引入文档定义好的一些函数
include('simple_html_dom.php');
然后用file_get_html函数获取url内容,其实返回一个可以处理的对象
$html = file_get_html('http://blog.deni.xin/');
接下来就可以处理所获得的想要的数据了
for($i=0;$i<8;$i++){
$title=$html->find('article.excerpt header h2',$i)->text();//获取第一个article下的h2的文本
$desc=$html->find('article.excerpt p.note',$i)->text();
$picurl=$html->find('article.excerpt div.focus a img',$i)->__get("src");//获取attr属性,类型jquery的attr()
if($picurl=="http://blog.deni.xin/wp-content/themes/d8/img/thumbnail.png"){
$picurl=soimg($title);
}
$url=$html->find('article.excerpt header h2 a',$i)->__get("href");
$articles[$i]=array('Title'=>$title,
'Description'=>$desc,
'PicUrl'=>$picurl,
'Url'=>$url);
}
$html->clear();
$this->replyNews($articles);
转载请注明:稻香的博客 » php用simple_html_dom获取解析html文档